Quelles sont ces langues qui défient l'auto-traduction ?
- Par Sophie Hardach
- BBC Future
Crédit photo, Getty Images
Imaginez que vous tombez sur un message qui pourrait contenir des informations vitales. Mais il y a un problème : vous ne comprenez pas un mot. Vous n'êtes même pas sûr de la langue dans laquelle il est écrit, parmi les milliers de langues existant dans le monde. Que faites-vous ?
Si le message est en français ou en espagnol, il suffit de le taper dans un moteur de traduction automatique pour résoudre instantanément le mystère et obtenir une réponse solide en anglais. Mais de nombreuses autres langues échappent encore à la traduction automatique, notamment des langues parlées par des millions de personnes, comme le wolof, le luganda, le twi et l'éwé en Afrique. La raison en est que les algorithmes qui alimentent ces moteurs apprennent à partir de traductions humaines - idéalement, des millions de mots de texte traduit.
Les institutions multilingues telles que le Parlement canadien, les Nations unies et l'Union européenne disposent d'une abondance de textes traduits dans des langues comme l'anglais, le français, l'espagnol et l'allemand. Leurs traducteurs humains produisent des flux de transcriptions et d'autres documents traduits. À lui seul, le Parlement européen produit en une décennie un trésor de données de 1,37 milliard de mots dans 23 langues.
A ne pas manquer sur BBC Afrique :
- Le phénomène poignant découvert chez les personnes sur le point de mourir
- Le Kente : le tissu ghanéen mise en scène par Louis Vuitton
- Le canal de Suez égyptien bloqué par un énorme porte-conteneurs - pourquoi c'est important ?
- Pourquoi nous allons vers une pénurie de caoutchouc, cet étonnant matériau nécessaire ?
- Un drapeau, du sang humain et pleins de controverses
Il n'existe cependant aucune montagne de données de ce type pour les langues qui peuvent être largement parlées mais qui ne sont pas traduites de manière aussi prolifique. On les appelle les langues à faibles ressources. Le matériel d'entraînement de secours pour ces langues est constitué de publications religieuses, dont la Bible, très traduite. Mais il s'agit d'un ensemble de données limité, qui ne suffit pas à former des robots de traduction précis et de grande envergure.
Google Translate permet actuellement de communiquer dans environ 108 langues différentes, tandis que Bing Translator de Microsoft en propose environ 70. Pourtant, il existe plus de 7 000 langues parlées dans le monde, et au moins 4 000 avec un système d'écriture.
Cette barrière linguistique peut poser un problème à tous ceux qui ont besoin de recueillir rapidement des informations précises et globales, y compris les services de renseignement.

Crédit photo, Getty Images
"Je dirais que plus un individu est intéressé par la compréhension du monde, plus il doit pouvoir accéder à des données qui ne sont pas en anglais", explique Carl Rubino, responsable de programme à l'IARPA, le bras de recherche des services de renseignement américains. "De nombreux défis auxquels nous sommes confrontés aujourd'hui, comme l'instabilité économique et politique, la pandémie de Covid-19 et le changement climatique, transcendent notre planète - et sont donc multilingues par nature."
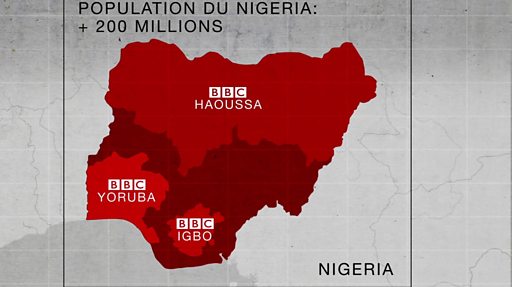
Former un traducteur humain ou un analyste du renseignement à une nouvelle langue peut prendre des années. Et même alors, cela peut ne pas être suffisant pour la tâche à accomplir. "Au Nigeria, par exemple, on parle plus de 500 langues", explique Rubino. "Même nos experts les plus réputés dans ce pays peuvent ne comprendre qu'une petite fraction de ces langues, voire aucune."

Pour briser cette barrière, l'IARPA finance des recherches visant à développer un système capable de trouver, de traduire et de résumer des informations dans n'importe quelle langue à faibles ressources, qu'il s'agisse de texte ou de parole.
Imaginez un moteur de recherche où l'utilisateur tape sa requête en anglais et reçoit une liste de documents résumés en anglais, traduits de la langue étrangère. Lorsqu'il clique sur l'un d'eux, le document traduit complet s'affiche. Bien que le financement provienne de l'IARPA, la recherche est menée ouvertement par des équipes concurrentes, et une grande partie des résultats a été publiée.
Kathleen McKeown, informaticienne à l'université de Columbia qui dirige l'une des équipes en compétition, voit des avantages au-delà de la communauté du renseignement. "L'objectif ultime est de faciliter l'interaction entre des personnes de cultures différentes et d'obtenir davantage d'informations à leur sujet", explique-t-elle.
Les équipes de recherche utilisent la technologie des réseaux neuronaux pour résoudre le problème, une forme d'intelligence artificielle qui imite certains aspects de la pensée humaine. Ces dernières années, les modèles de réseaux neuronaux ont révolutionné le traitement du langage. Au lieu de simplement mémoriser des mots et des phrases, ils peuvent en apprendre le sens. Ils peuvent déterminer, à partir du contexte, que des mots tels que "chien", "caniche" et le mot français "chien" expriment tous des concepts similaires, même s'ils semblent très différents à première vue.
Pour ce faire, cependant, les modèles doivent généralement parcourir des millions de pages de texte d'entraînement. Le défi consiste à les amener à apprendre à partir de plus petites quantités de données, comme le font les humains. Après tout, les êtres humains n'ont pas besoin de lire des années d'archives parlementaires pour apprendre une langue.

"Chaque fois que vous étudiez une langue, vous ne verrez jamais, au grand jamais, la quantité de données que les systèmes de traduction automatique d'aujourd'hui utilisent pour apprendre la traduction de l'anglais vers le français", explique Regina Barzilay, informaticienne au MIT et membre d'une autre des équipes en compétition. "Vous voyez une infime, minuscule fraction, qui vous permet de généraliser et de comprendre le français. Donc, de la même manière, vous voulez examiner la prochaine génération de systèmes de traduction automatique qui peuvent faire un excellent travail même sans avoir ce genre de comportement gourmand en données."
Pour s'attaquer au problème, chaque équipe est divisée en petits groupes de spécialistes qui résolvent un aspect du système. Les principaux composants sont des technologies de recherche automatique, de reconnaissance vocale, de traduction et de résumé de texte, toutes adaptées aux langues à faibles ressources. Depuis le début du projet de quatre ans en 2017, les équipes ont travaillé sur huit langues différentes, dont le swahili, le tagalog, le somali et le kazakh.

Crédit photo, Getty Images
La collecte de textes et de paroles sur le Web, sous la forme d'articles d'actualité, de blogs et de vidéos, a constitué une avancée majeure. Grâce aux utilisateurs du monde entier qui publient du contenu dans leur langue maternelle, il existe une masse croissante de données en ligne pour de nombreuses langues à faibles ressources.
"Si vous faites une recherche sur Internet et que vous voulez des données en somali, vous obtenez des centaines de millions de mots, sans problème", explique Scott Miller, informaticien à l'université de Californie du Sud, qui codirige l'une des équipes de recherche travaillant sur ce sujet. "Vous pouvez obtenir du texte dans presque toutes les langues en assez grande quantité sur le web".
Ces données en ligne ont tendance à être monolingues, ce qui signifie que les articles ou les vidéos en somali sont uniquement dans cette langue, et ne sont pas accompagnés d'une traduction anglaise parallèle. Mais M. Miller explique que les modèles de réseaux neuronaux peuvent être pré-entraînés sur de telles données monolingues dans de nombreuses langues différentes.
On pense qu'au cours de leur préformation, les modèles neuronaux apprennent certaines structures et caractéristiques du langage humain en général, qu'ils peuvent ensuite appliquer à une tâche de traduction. La nature de ces structures et caractéristiques reste un peu mystérieuse. "Personne ne sait vraiment quelles structures ces modèles apprennent réellement", déclare Miller. "Ils ont des millions de paramètres".
Mais une fois pré-entraînés sur de nombreuses langues, les modèles neuronaux peuvent apprendre à traduire entre les différentes langues en utilisant très peu de matériel d'entraînement bilingue, appelé données parallèles. Quelques centaines de milliers de mots de données parallèles suffisent, soit environ la longueur de quelques romans.
Le moteur de recherche multilingue sera capable de passer au peigne fin la parole humaine ainsi que le texte, ce qui pose une autre série de problèmes complexes. Par exemple, la technologie de reconnaissance et de transcription de la parole a généralement du mal avec les sons, les noms et les lieux qu'elle n'a jamais rencontrés auparavant.
"Mon exemple serait un pays qui est peut-être relativement obscur pour l'Occident, et peut-être qu'un politicien est assassiné", explique Peter Bell, un spécialiste de la technologie vocale à l'Université d'Édimbourg qui fait partie de l'une des équipes qui tentent de résoudre ce problème. "Son nom est maintenant très important, mais auparavant, il était obscur, il était inconnu. Alors comment faire pour trouver le nom de cet homme politique dans votre audio ?"

Une solution utilisée par Bell et ses collaborateurs consiste à revenir aux mots qui ont été initialement transcrits avec une certaine incertitude, indiquant que la machine ne les connaissait pas. Après une nouvelle inspection, l'un d'entre eux peut s'avérer être le nom de l'homme politique, jusque-là obscur et peu connu.
Une fois qu'il a trouvé et traduit les informations pertinentes, le moteur de recherche les résume pour l'utilisateur. C'est au cours de ce processus de résumé que les modèles neuronaux affichent certains de leurs comportements les plus étranges : ils hallucinent.

Crédit photo, Getty Images
Imaginez que vous recherchez un reportage sur des manifestants qui ont pris d'assaut un bâtiment le lundi. Mais le résumé qui s'affiche indique qu'ils ont pris d'assaut le bâtiment le jeudi. Cela s'explique par le fait que le modèle neuronal s'est appuyé sur ses connaissances de base, basées sur des millions de pages de texte d'entraînement, pour résumer le reportage. Dans ces textes, il y avait plus d'exemples de personnes prenant d'assaut des bâtiments le jeudi, il en a donc conclu que cela devait également s'appliquer au dernier exemple.
De même, les modèles neuronaux peuvent insérer des dates ou des chiffres dans un résumé. Les informaticiens appellent cela "halluciner".

"Ces modèles de réseaux neuronaux, ils sont si puissants, ils ont mémorisé beaucoup de langues, ils ajoutent des mots qui n'étaient pas dans la source", explique Mirella Lapata, informaticienne à l'université d'Édimbourg, qui développe un élément de résumé pour l'une des équipes.
Lapata et ses collègues ont évité ce problème en extrayant des mots-clés de chaque document, plutôt que de demander à la machine de le résumer en phrases. Les mots-clés sont moins élégants que les phrases, mais ils limitent la tendance des modèles à écrire de la poésie robotique.
Bien que le moteur de recherche soit conçu pour les langues vivantes, le projet comprend un sous-groupe travaillant sur les langues qui n'ont pas été parlées depuis des milliers d'années. Ces langues anciennes sont extrêmement pauvres en ressources, car beaucoup ne survivent que sous forme de fragments de texte. Elles constituent un terrain d'essai utile pour les techniques qui pourraient ensuite être appliquées aux langues modernes à faibles ressources.
L'étudiant en doctorat de Barzilay au MIT, Jiaming Luo, et ses collaborateurs ont mis au point un algorithme capable de déterminer si certaines langues anciennes ont des survivants modernes. Ils lui ont donné une longueur d'avance en lui fournissant des informations de base sur ces langues et sur les aspects généraux de l'évolution des langues. Grâce à ces connaissances, le modèle a pu faire des découvertes par lui-même, en utilisant seulement une petite quantité de données. Il a ainsi correctement déterminé que l'ougaritique, une langue ancienne du Proche-Orient, est apparentée à l'hébreu. Il a également conclu que l'ibérique, une ancienne langue européenne, est plus proche du basque que des autres langues européennes, mais pas suffisamment pour être un proche parent.

M. Barzilay espère que de telles approches pourraient inspirer un changement plus large et rendre les modèles neuronaux moins gourmands en données. "Notre dépendance à l'égard d'énormes données parallèles - c'est une faiblesse du système", dit-elle. "Donc si vous produisez vraiment une bonne technologie, que ce soit pour le déchiffrage, pour les petites langues, cela va faire avancer le domaine."
Les équipes ont toutes réussi à produire des versions de base du moteur de recherche multilingue, en l'affinant avec chaque nouvelle langue. M. Rubino, responsable du programme IARPA, est convaincu que de telles technologies pourraient changer la façon dont les renseignements sont recueillis. "Nous aurons en effet la possibilité de révolutionner la façon dont nos analystes apprennent à partir de données en langue étrangère, en permettant aux analystes monolingues anglophones d'accéder à des données multilingues avec lesquelles ils ne pouvaient auparavant pas travailler", dit-il.

Crédit photo, Getty Images
Alors que les analystes du renseignement tentent d'ouvrir les langues à faibles ressources de l'extérieur, les locuteurs natifs de ces langues prennent également les choses en main. Eux aussi veulent avoir accès à des informations urgentes dans d'autres langues - non pas à des fins d'espionnage, mais pour améliorer leur vie quotidienne.
"Lorsque la pandémie de Covid-19 est survenue, il y a eu un besoin soudain de traduire des conseils de santé de base dans de nombreuses langues. Et nous ne pouvions pas le faire avec des modèles de traduction automatique, en raison de la qualité", explique David Ifeoluwa Adelani, doctorant en informatique à l'université de la Sarre à Sarrebruck, en Allemagne. "Je pense que cela nous a vraiment appris qu'il est important que nous disposions d'une technologie qui fonctionne pour les langues à faibles ressources, surtout en cas de besoin."

Originaire du Nigeria et locuteur natif du Yorùbá, Adelani a construit une base de données Yorùbá-anglais dans le cadre d'un projet à but non lucratif intitulé "Cracking the Language Barrier for a Multilingual Africa" (Briser la barrière linguistique pour une Afrique multilingue). Lui et son équipe ont créé un nouvel ensemble de données en rassemblant des scénarios de films, des nouvelles, de la littérature et des discours publics traduits. Ils ont ensuite utilisé cet ensemble de données pour affiner un modèle déjà entraîné sur des textes religieux, tels que les publications des Témoins de Jéhovah, et améliorer ses performances. Des efforts similaires sont en cours pour d'autres langues africaines comme l'éwé, le fongbe, le twi et le luganda, avec l'aide de communautés de base comme "Masakhane", un réseau de chercheurs de toute l'Afrique.
Un jour, nous utiliserons peut-être tous des moteurs de recherche multilingues dans notre vie quotidienne, débloquant ainsi les connaissances du monde entier d'un simple clic. D'ici là, la meilleure façon de comprendre une langue à faible ressource est probablement de l'apprendre et de participer au dialogue humain multilingue en ligne qui forme les robots de traduction du monde entier.